
GDKDEによるAdversarial Attackの理論
勉強していたことをまとめたものです。一部誤りがあるかもしれません。
マルウェア文脈におけるAdversarial Attackを想定しています。
論文: Evasion attacks against machine learning at test time(2013)
1. KDE(カーネル密度推定)の基礎
カーネル密度推定(Kernel Density Estimation, KDE) は与えられたデータから、その下にある未知の確率密度関数を推定するノンパラ手法。
ヒストグラムのようにビンにデータ点を数える代わりに、各データ点の近傍になめらかな「カーネル関数」(例えばガウス関数)による山(コブ)を配置し、それらを重ね合わせることで全体の密度関数を推定する。
KDEの数式表現は次の通り。データ点を とし、カーネル関数を , バンド幅(平滑化パラメータ)を とすると、ある点 での推定密度 は以下で与えられる。
この式では、各データ点 について、その周りに幅 のカーネル関数 を置き、データで平均を取る。典型的には、ガウス核(Gaussian kernel) と呼ばれる標準正規分布(平均0, 分散1のガウス関数)
をカーネルに採用することが多い。
こうすることで、 はガウス分布の重ね合わせ(混合分布)として計算され、データ点が密集している領域では多くのカーネルが重なるため高い密度推定値が得られ、データがまばらな領域では密度が低く推定される。
直感的には、各データ点が「小さな山」を形成し、その山の総和が確率密度の推定結果になる。
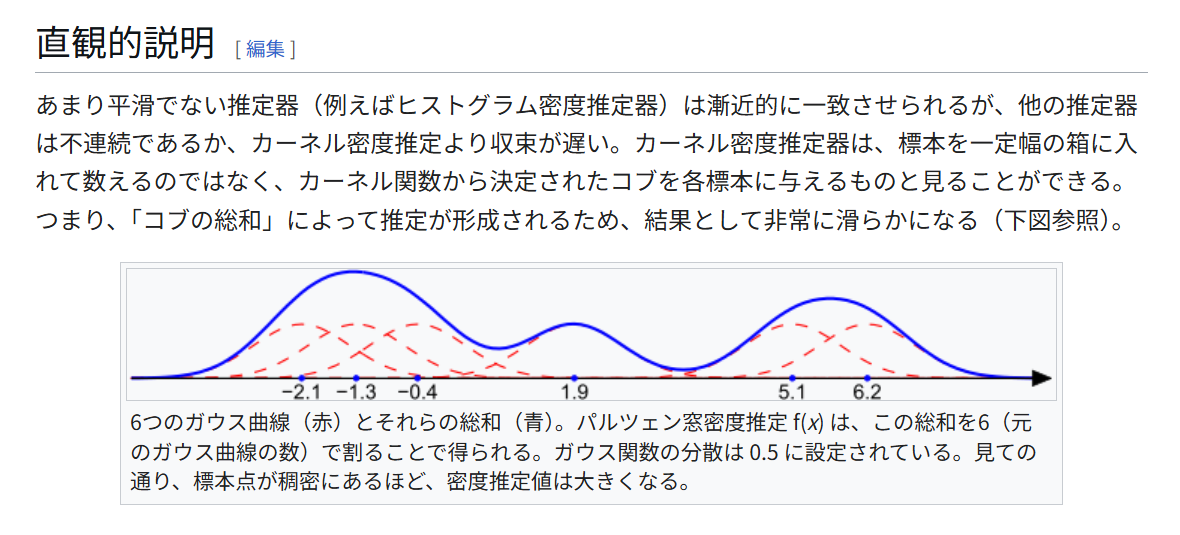 引用:
引用: 2. GDKDEとは
GDKDE(Gradient Descent and KDE)は、ラプラシアンカーネルを用いた密度推定を攻撃アルゴリズムに組み込むことで、より「自然な」攻撃を行うものである。
勾配降下法(Gradient Descent)による最適化の文脈では、攻撃者はある損失関数 を最小化するためにマルウェアサンプル を段階的に更新していく。マルウェア検知回避のための基本的な損失関数は、モデルが出力する「マルウェアであるスコア」を表す関数 (この値が大きいほどマルウェアらしいことを示す, SigmoidやLogitなど)を低減させることが目的になる。
しかし、 だけを最小化すると、しばしば決定境界の「穴」のような低密度領域(すなわち局所最小値)にサンプルが移動し、不自然な特徴を持つサンプルになってしまう恐れがある。そこでGDKDEでは、損失関数に密度ペナルティ項を追加し、サンプルがクリーンウェアデータの高密度領域から極端に外れないように誘導する。
Attack Strategy
攻撃者の最適な攻撃戦略は、マルウェアサンプル に対し、 またはその推定値 を最小化するサンプル を見つけることである。ただし、 は からの距離が、以下の制約を満たす必要がある。
一般にこれは非線形最適化問題となる。これを解く方法として勾配降下法を用いる。しかし、 は非凸関数である可能性があり、勾配降下法では大域的最適解に到達できない場合がある。
代わりに、降下経路が平坦な領域(局所最小値)に到達する可能性がある。これはサンプルの支持の外側、すなわち の領域にある場合である。この場合、攻撃サンプルが回避成功するかどうかは 未サポート領域における の振る舞いに依存してしまい、成功を確信できない。
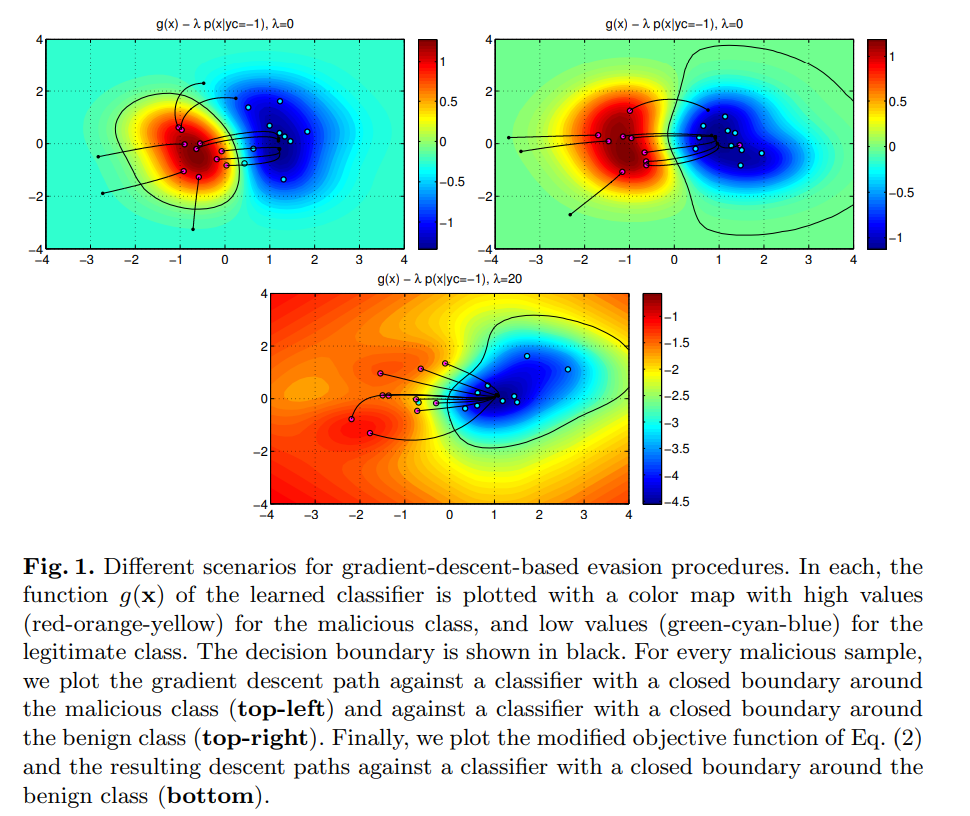
引用: Evasion attacks against machine learning at test time(2013)
このために、攻撃者が回避成功の確率を高めるには、クリーンウェアが密集する領域から攻撃ポイントを選択すべきである。こうした領域では の推定値がより信頼度高く(実際のに近づく)、その値は負の方向に向かう傾向がある。
この欠点を克服するため、攻撃目的(loss)関数に追加の要素し、次の目的(loss)関数を定義する。
ただし、 はトレードオフを調整するハイパーパラメータである。第一項 は「サンプル がマルウェアと判定される傾向」を表し、第二項は がクリーンウェアの密集する領域にあるほど大きくなる。この を小さくする(最小化する)ことが攻撃者の目的とする。また、True Labelの と検知器が導くラベル は区別して扱う。
バイナリ特徴量における はラプラシアンカーネル(もしくはRBFカーネル)を使えば良い。
ここで、 は と の ノルム(ハミング距離)であり、 は検知器 がクリーンウェアと判定する(つまりとなる)サンプルであり、攻撃者が推定のために用意できるサンプルの数である。すなわち、攻撃者の戦略は次のように置き換わる。
直感的にいえば、 を減少させるには、
(a) マルウェア分類器の出力するマルウェアスコア を下げつつ
(b) をクリーンウェアサンプルの分布が高い領域(すなわち が高い領域に留まらせる
という2点を解決する必要がある。この密度項により、勾配降下法が導く方向は単に分類器を騙すだけではなく、「よりクリーンウェアに似せる」方向となる。その結果、生成された攻撃サンプルはモデルから見てより本物のクリーンウェアサンプルらしい特徴を持つようになり、検知をすり抜けやすくなる。
このアプローチは従来から知られるMimicry攻撃(正常動作の模倣攻撃)と同様に、攻撃対象のシステムに正常データを真似た痕跡を持ち込むことで検知を回避する効果がある。
そのため、以降ではこの項をmimicry componentと呼ぶ。
mimicry componentを使用した場合()、勾配降下は のみを最小化する場合() と比較して、明らかに非最適な経路をたどることを指摘しておく。そのため、 の時に達成される と同じ値に到達するには、より多くの変更が必要になる可能性がある。しかし、 勾配降下法は局所最小値に陥る可能性があるためこれが重要となる。
勾配降下の手順では、 の勾配 を計算し、その反対方向へ少しずつ を更新していく。 の定義から、勾配は
となる。したがって、 が「よりマルウェアスコアを下げる方向」を示すのに対し、 は「より良性データが多い領域へ向かう方向」を示す。
によってこの二つのバランスが調整されることになる。 なら従来通り分類器スコアだけを最小化し、が大きいほど「クリーンウェアらしさ」を重視した更新となる。結果として、「適切な 」のもとで勾配降下法を用いると、攻撃サンプルは徐々に検知モデルの決定境界をすり抜けつつ、クリーンウェアのデータ分布に溶け込むような方向へ変化していく。この密度推定項は低密度領域にサンプルが迷い込むことを防ぐ一種の「ペナルティ項」として働くため、攻撃を加速させるものではない。勾配降下法が局所解に陥ったり不自然な解を見つけたりするのを緩和する。
ここでいう「適切な 」は、 とのバランスを取れるように設定するべきであり、
であることから、 を考慮しなければならない。目的関数内の の値を、 の値が識別関数 の値の範囲と同等(またはそれ以上)になるように選択する必要がある。
3. アルゴリズム
- 初期設定: 攻撃対象のマルウェアサンプルを とする。これが初めはモデルにマルウェアと分類されるポイントである。攻撃者は許容できる改変の範囲(例: 元のプログラムからの距離 )やステップサイズ , 密度項の重み , 収束判定しきい値 を決定する
- 勾配計算: 現在のサンプル における損失関数 の勾配 を計算する。これは分類器の出力スコアに関する勾配と、クリーンウェアデータ密度の勾配を組み合わせたものである。
- サンプルの更新: を次のステップでは と更新する。つまり、 の方向に沿ってステップサイズ だけサンプルを移動させる。この操作で分類器の出力スコアを下げつつ、クリーンウェア密度の高い方向へサンプルをわずかに変化させる。
- 制約の適用: 更新後のサンプルが元のサンプルを超えてしまった場合、そのサンプルを許容範囲内に射影する
- 反復と収束: 上記の勾配計算と更新を繰り返し行う。回避成功または変更量が収束判定しきい値 を下回った場合、ループを終了する。

引用: Evasion attacks against machine learning at test time(2013)